Querying OneLake Data as a Graph
Summary
In this tutorial, you will:
- Create a lakehouse in Microsoft OneLake and load example data;
- Deploy PuppyGraph via Docker and query OneLake data as a graph via OneLake table APIs for Iceberg.
Prerequisites
-
OneLake
- A Microsoft Fabric workspace and a user account with at least the Contributor role in that workspace.
- A service principal in Microsoft Entra ID with permissions to read tables in the lakehouse to create later. For more details on setting up authentication, please refer to preparing for authentication.
It is also recommended to read the following official documents to get familiar with OneLake table APIs for Iceberg and lakehouse:
-
Docker
Please ensure that docker is available. The installation can be verified by running:
See https://www.docker.com/get-started/ for more details on Docker.
Data Preparation
 Enable automatic table virtualization of Delta Lake tables to the Iceberg format by turning on the delegated OneLake setting named Enable Delta Lake to Apache Iceberg table format virtualization in your workspace settings.
Enable automatic table virtualization of Delta Lake tables to the Iceberg format by turning on the delegated OneLake setting named Enable Delta Lake to Apache Iceberg table format virtualization in your workspace settings.
Create a schema-enabled lakehouse in your Fabric workspace.
Create a notebook in the lakehouse, choose Spark SQL as the language, and run the following SQL commands to create the schema and tables, then insert data.
Spark SQL
CREATE SCHEMA modern;
CREATE TABLE modern.person (
id string,
name string,
age int
) USING DELTA;
INSERT INTO modern.person VALUES
('v1', 'marko', 29),
('v2', 'vadas', 27),
('v4', 'josh', 32),
('v6', 'peter', 35);
CREATE TABLE modern.software (
id string,
name string,
lang string
) USING DELTA;
INSERT INTO modern.software VALUES
('v3', 'lop', 'java'),
('v5', 'ripple', 'java');
CREATE TABLE modern.created (
id string,
from_id string,
to_id string,
weight double
) USING DELTA;
INSERT INTO modern.created VALUES
('e9', 'v1', 'v3', 0.4),
('e10', 'v4', 'v5', 1.0),
('e11', 'v4', 'v3', 0.4),
('e12', 'v6', 'v3', 0.2);
CREATE TABLE modern.knows (
id string,
from_id string,
to_id string,
weight double
) USING DELTA;
INSERT INTO modern.knows VALUES
('e7', 'v1', 'v2', 0.5),
('e8', 'v1', 'v4', 1.0);
You should now see the tables created in the lakehouse under the modern schema. Confirm that your Delta Lake table has converted successfully to the virtual Iceberg format. You can do this by examining the directory behind the table. See more details in virtualizing Delta Lake tables as Iceberg.
The above SQL creates the following tables:
| id | name | age |
|---|---|---|
| v1 | marko | 29 |
| v2 | vadas | 27 |
| v4 | josh | 32 |
| v6 | peter | 35 |
| id | name | lang |
|---|---|---|
| v3 | lop | java |
| v5 | ripple | java |
| id | from_id | to_id | weight |
|---|---|---|---|
| e7 | v1 | v2 | 0.5 |
| e8 | v1 | v4 | 1.0 |
| id | from_id | to_id | weight |
|---|---|---|---|
| e9 | v1 | v3 | 0.4 |
| e10 | v4 | v5 | 1.0 |
| e11 | v4 | v3 | 0.4 |
| e12 | v6 | v3 | 0.2 |
Deployment
Start a PuppyGraph docker container:
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -e PUPPYGRAPH_PASSWORD=puppygraph123 -e QUERY_TIMEOUT=5m -d --name puppy --rm --pull=always puppygraph/puppygraph:0.101
Log into the PuppyGraph Web UI at http://localhost:8081 with puppygraph as the username and puppygraph123 as the password.
Modeling a Graph
We then define a graph on top of the data tables we just created. Actually, this is the "Modern" graph defined by Apache Tinkerpop.
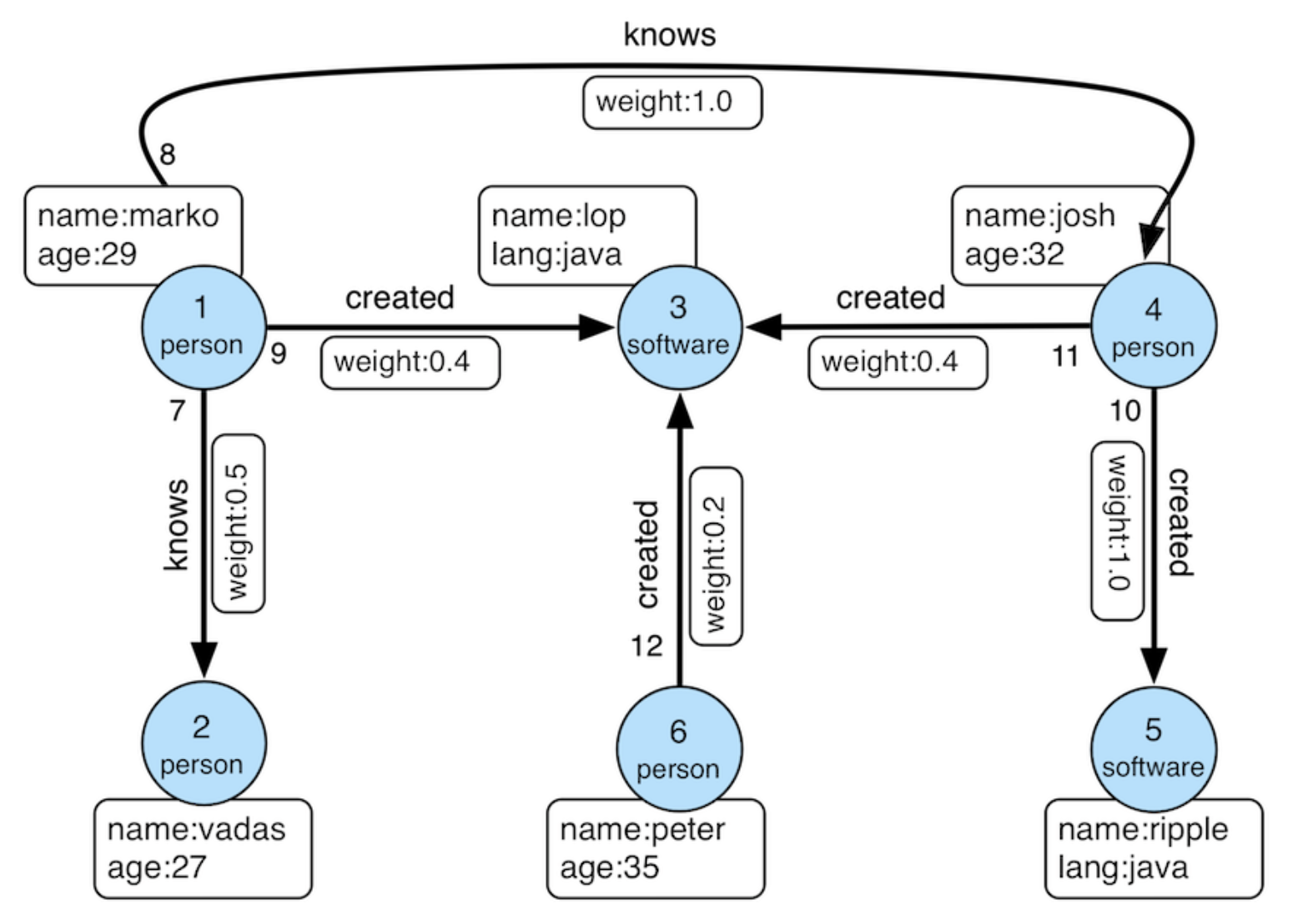
Modern Graph
PuppyGraph defines graph modeling by using a schema. There are two methods to model the graph:
- Use the graph schema builder to build the schema in the Web UI.
- Click on Create graph schema to create a new graph schema.
- Configure the data source.
- Map data to graph step by step.
- Compose a schema JSON file and upload it.
- Replace the placeholders in the file
schema.jsonbelow. - Choose the file and upload it.
- Replace the placeholders in the file
In this tutorial we use the second method, while for the first method, you essentially fill in the same information. Create a file named schema.json with the following content. Replace the placeholders with your actual values to configure the connection using the Iceberg REST Catalog via OneLake Table APIs for Iceberg:
| Placeholder | Description |
|---|---|
<fabric_workspace_id> |
The ID of your Microsoft Fabric workspace |
<fabric_data_item_id> |
The ID of the lakehouse data item |
<client_id> |
The client ID of the service principal |
<client_secret> |
The client secret of the service principal |
<tenant_id> |
Your Microsoft Entra ID tenant ID - see endpoint |
schema.json
{
"catalogs": [
{
"name": "test_onelake_table_api",
"type": "iceberg",
"metastore": {
"type": "rest",
"uri": "https://onelake.table.fabric.microsoft.com/iceberg",
"warehouse": "<fabric_workspace_id>/<fabric_data_item_id>",
"security": "OAUTH2",
"credential": "<client_id>:<client_secret>",
"enableIcebergMetaCache": "true",
"icebergMetaCacheTTL": "180",
"scope": "https://storage.azure.com/.default",
"oauthServerUri": "https://login.microsoftonline.com/<tenant_id>/oauth2/v2.0/token"
},
"storage": {
"type": "AzureDLS2",
"clientId": "<client_id>",
"clientSecret": "<client_secret>",
"clientEndpoint": "https://login.microsoftonline.com/<tenant_id>/oauth2/v2.0/token"
}
}
],
"graph": {
"vertices": [
{
"label": "person",
"oneToOne": {
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "person"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
}
]
}
},
{
"label": "software",
"oneToOne": {
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "software"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
},
{
"type": "STRING",
"field": "lang",
"alias": "lang"
}
]
}
}
],
"edges": [
{
"label": "created",
"fromVertex": "person",
"toVertex": "software",
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "created"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "from_id",
"alias": "puppy_from_from_id"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "to_id",
"alias": "puppy_to_to_id"
}
]
}
},
{
"label": "knows",
"fromVertex": "person",
"toVertex": "person",
"tableSource": {
"catalog": "test_onelake_table_api",
"schema": "modern",
"table": "knows"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "from_id",
"alias": "puppy_from_from_id"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "puppy_to_id"
}
]
}
}
]
}
}
Log into PuppyGraph Web UI at http://localhost:8081 with username puppygraph and password puppygraph123.
Upload the schema by selecting the file schema.json in the Upload Graph Schema JSON block and clicking on Upload.
Once the schema is uploaded, the schema page shows the visualized graph schema.
Alternative: Schema Uploading via CLI
Alternatively, run the following command to upload the schema file:
curl -XPOST -H "content-type: application/json" --data-binary @./schema.json --user "puppygraph:puppygraph123" localhost:8081/schema
The response shows that graph schema has been uploaded successfully:
Query the Graph
Navigate to Query in the Web UI. Use Graph Query for Gremlin/openCypher queries with visualization.
Example Queries
-
Retrieve a vertex named 'marko'.
Gremlin:
openCypher:
-
Retrieve the paths from "marko" to the software created by those whom "marko" knows.
Gremlin:
openCypher:
Cleanup
To stop and remove the PuppyGraph Docker container, run: