Querying Oracle Data as a Graph
Summary
In this tutorial, you will:
- Set up an Oracle database with example data.
- Start a PuppyGraph Docker container and query the Oracle data as a graph.
Prerequisites
- Please ensure that
docker composeis available. The installation can be verified by running:
See https://docs.docker.com/compose/install/ for Docker Compose installation instructions and https://www.docker.com/get-started/ for more details on Docker.
- You need an Oracle account to pull the Oracle Docker image.
- Accessing the PuppyGraph Web UI requires a browser. However, the tutorial offers alternative instructions for those who wish to exclusively use the CLI.
Deployment
 Log in to the Oracle Container Registry.
Log in to the Oracle Container Registry.
Browse the Database section and select Enterprise with version 21.3.0.0.
Accept the license agreement for the Oracle container you have selected.
Log in to Docker using your Oracle account credentials.
Create a file docker-compose.yaml with the following content:
docker-compose.yaml
services:
puppygraph:
image: puppygraph/puppygraph:stable
pull_policy: always
container_name: puppygraph
environment:
- PUPPYGRAPH_USERNAME=puppygraph
- PUPPYGRAPH_PASSWORD=puppygraph123
networks:
oracle_net:
ports:
- "8081:8081"
- "8182:8182"
- "7687:7687"
oracle-db:
image: container-registry.oracle.com/database/enterprise:21.3.0.0
container_name: oracle-db
environment:
- ORACLE_SID=ORCLCDB
- ORACLE_PWD=your_password
networks:
oracle_net:
ports:
- "1521:1521"
- "5500:5500"
networks:
oracle_net:
name: puppy-oracle
Then run the following command to start Oracle and PuppyGraph:
[+] Running 1/1
✔ puppygraph Pulled
[+] Running 3/3
✔ Network puppy-oracle Created
✔ Container puppygraph Started
✔ Container oracle-db Started
Data Preparation
This tutorial is designed to be comprehensive and standalone, so it includes steps to populate data in Oracle. In practical scenarios, PuppyGraph can query data directly from your existing Oracle databases.
Verify Oracle is Running
After starting the Oracle container, it may take several minutes for the database to initialize. Use the following command to monitor the logs and ensure Oracle is fully ready before proceeding:
When the database is ready, you will see the following message: Access the Oracle client shell:
The shell prompt will appear as:
Connected to:
Oracle Database 21c Enterprise Edition Release 21.0.0.0.0 - Production
Version 21.3.0.0.0
SQL>
Then execute the following SQL statements in the shell to create tables and insert data.
-- Switch to the PDB
ALTER SESSION SET CONTAINER = ORCLPDB1;
-- Create a new user and grant permissions
CREATE USER MODERN IDENTIFIED BY modern_password;
GRANT CONNECT, RESOURCE TO MODERN;
ALTER USER MODERN QUOTA UNLIMITED ON USERS;
ALTER USER MODERN DEFAULT TABLESPACE USERS;
GRANT CREATE SESSION, CREATE TABLE, INSERT ANY TABLE TO MODERN;
-- Switch to the MODERN schema
ALTER SESSION SET CURRENT_SCHEMA = MODERN;
-- Create the PERSON table and insert data
CREATE TABLE PERSON (
ID VARCHAR2(255),
NAME VARCHAR2(255),
AGE NUMBER(10)
);
-- Insert data into the PERSON table
INSERT INTO PERSON (ID, NAME, AGE) VALUES ('v1', 'marko', 29);
INSERT INTO PERSON (ID, NAME, AGE) VALUES ('v2', 'vadas', 27);
INSERT INTO PERSON (ID, NAME, AGE) VALUES ('v4', 'josh', 32);
INSERT INTO PERSON (ID, NAME, AGE) VALUES ('v6', 'peter', 35);
-- Create the SOFTWARE table and insert data
CREATE TABLE SOFTWARE (
ID VARCHAR2(255),
NAME VARCHAR2(255),
LANG VARCHAR2(255)
);
-- Insert data into the SOFTWARE table
INSERT INTO SOFTWARE (ID, NAME, LANG) VALUES ('v3', 'lop', 'java');
INSERT INTO SOFTWARE (ID, NAME, LANG) VALUES ('v5', 'ripple', 'java');
-- Create the CREATED table and insert data
CREATE TABLE CREATED (
ID VARCHAR2(255),
FROM_ID VARCHAR2(255),
TO_ID VARCHAR2(255),
WEIGHT FLOAT
);
-- Insert data into the CREATED table
INSERT INTO CREATED (ID, FROM_ID, TO_ID, WEIGHT) VALUES ('e9', 'v1', 'v3', 0.4);
INSERT INTO CREATED (ID, FROM_ID, TO_ID, WEIGHT) VALUES ('e10', 'v4', 'v5', 1.0);
INSERT INTO CREATED (ID, FROM_ID, TO_ID, WEIGHT) VALUES ('e11', 'v4', 'v3', 0.4);
INSERT INTO CREATED (ID, FROM_ID, TO_ID, WEIGHT) VALUES ('e12', 'v6', 'v3', 0.2);
-- Create the KNOWS table and insert data
CREATE TABLE KNOWS (
ID VARCHAR2(255),
FROM_ID VARCHAR2(255),
TO_ID VARCHAR2(255),
WEIGHT FLOAT
);
-- Insert data into the KNOWS table
INSERT INTO KNOWS (ID, FROM_ID, TO_ID, WEIGHT) VALUES ('e7', 'v1', 'v2', 0.5);
INSERT INTO KNOWS (ID, FROM_ID, TO_ID, WEIGHT) VALUES ('e8', 'v1', 'v4', 1.0);
The above SQL creates the following tables:
| ID | NAME | AGE |
|---|---|---|
| v1 | marko | 29 |
| v2 | vadas | 27 |
| v4 | josh | 32 |
| v6 | peter | 35 |
| ID | NAME | LANG |
|---|---|---|
| v3 | lop | java |
| v5 | ripple | java |
| ID | FROM_ID | TO_ID | WEIGHT |
|---|---|---|---|
| e7 | v1 | v2 | 0.5 |
| e8 | v1 | v4 | 1.0 |
| ID | FROM_ID | TO_ID | WEIGHT |
|---|---|---|---|
| e9 | v1 | v3 | 0.4 |
| e10 | v4 | v5 | 1.0 |
| e11 | v4 | v3 | 0.4 |
| e12 | v6 | v3 | 0.2 |
Exit the Oracle client shell:
Modeling a Graph
We then define a graph on top of the data tables we just created. Actually, this is the "Modern" graph defined by Apache Tinkerpop.
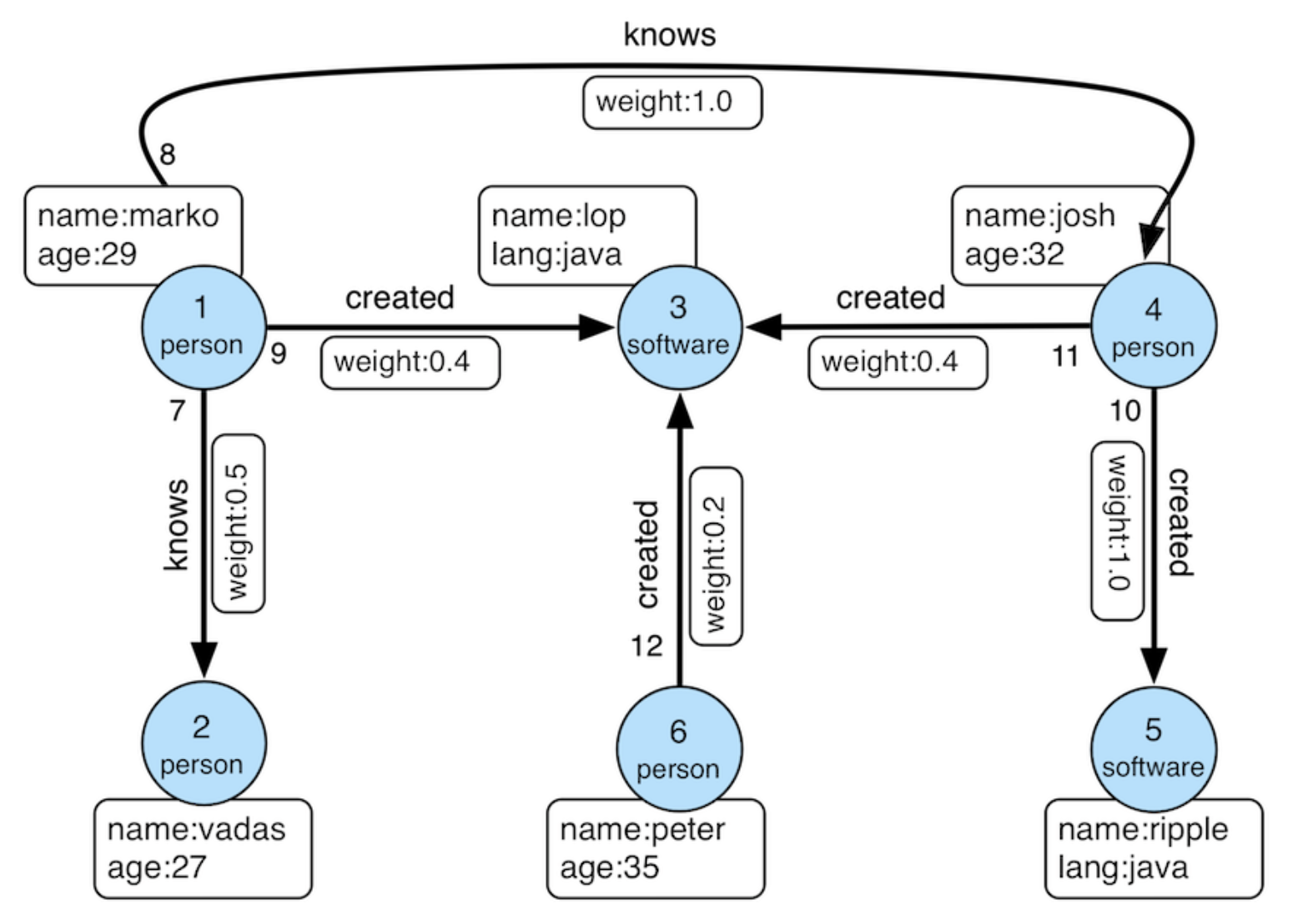
Modern Graph
A schema instructs PuppyGraph on mapping data from the Oracle into a graph. PuppyGraph offers various methods for schema creation. For this tutorial, we've already prepared a schema to help save time.
Create a PuppyGraph schema file schema.json with the following content:
schema.json
{
"catalogs": [
{
"name": "oracle_catalog",
"type": "oracle",
"jdbc": {
"username": "MODERN",
"password": "modern_password",
"jdbcUri": "jdbc:oracle:thin:@oracle-db:1521/ORCLPDB1",
"driverClass": "oracle.jdbc.OracleDriver"
}
}
],
"graph": {
"vertices": [
{
"label": "person",
"oneToOne": {
"tableSource": {
"catalog": "oracle_catalog",
"schema": "MODERN",
"table": "PERSON"
},
"id": {
"fields": [
{
"type": "String",
"field": "ID",
"alias": "id"
}
]
},
"attributes": [
{
"type": "DECIMAL(10,0)",
"field": "AGE",
"alias": "age"
},
{
"type": "String",
"field": "NAME",
"alias": "name"
}
]
}
},
{
"label": "software",
"oneToOne": {
"tableSource": {
"catalog": "oracle_catalog",
"schema": "MODERN",
"table": "SOFTWARE"
},
"id": {
"fields": [
{
"type": "String",
"field": "ID",
"alias": "id"
}
]
},
"attributes": [
{
"type": "String",
"field": "LANG",
"alias": "lang"
},
{
"type": "String",
"field": "NAME",
"alias": "name"
}
]
}
}
],
"edges": [
{
"label": "knows",
"fromVertex": "person",
"toVertex": "person",
"tableSource": {
"catalog": "oracle_catalog",
"schema": "MODERN",
"table": "KNOWS"
},
"id": {
"fields": [
{
"type": "String",
"field": "ID",
"alias": "id"
}
]
},
"fromId": {
"fields": [
{
"type": "String",
"field": "FROM_ID",
"alias": "from_id"
}
]
},
"toId": {
"fields": [
{
"type": "String",
"field": "TO_ID",
"alias": "to_id"
}
]
},
"attributes": [
{
"type": "Float",
"field": "WEIGHT",
"alias": "weight"
}
]
},
{
"label": "created",
"fromVertex": "person",
"toVertex": "software",
"tableSource": {
"catalog": "oracle_catalog",
"schema": "MODERN",
"table": "CREATED"
},
"id": {
"fields": [
{
"type": "String",
"field": "ID",
"alias": "id"
}
]
},
"fromId": {
"fields": [
{
"type": "String",
"field": "FROM_ID",
"alias": "from_id"
}
]
},
"toId": {
"fields": [
{
"type": "String",
"field": "TO_ID",
"alias": "to_id"
}
]
},
"attributes": [
{
"type": "Float",
"field": "WEIGHT",
"alias": "weight"
}
]
}
]
}
}
Log into PuppyGraph Web UI at http://localhost:8081 with username puppygraph and password puppygraph123.
PuppyGraph Login
Upload the schema by selecting the file schema.json in the Upload Graph Schema JSON block and clicking on Upload.
Upload Schema Page
Once the schema is uploaded, the schema page shows the visualized graph schema as follows.
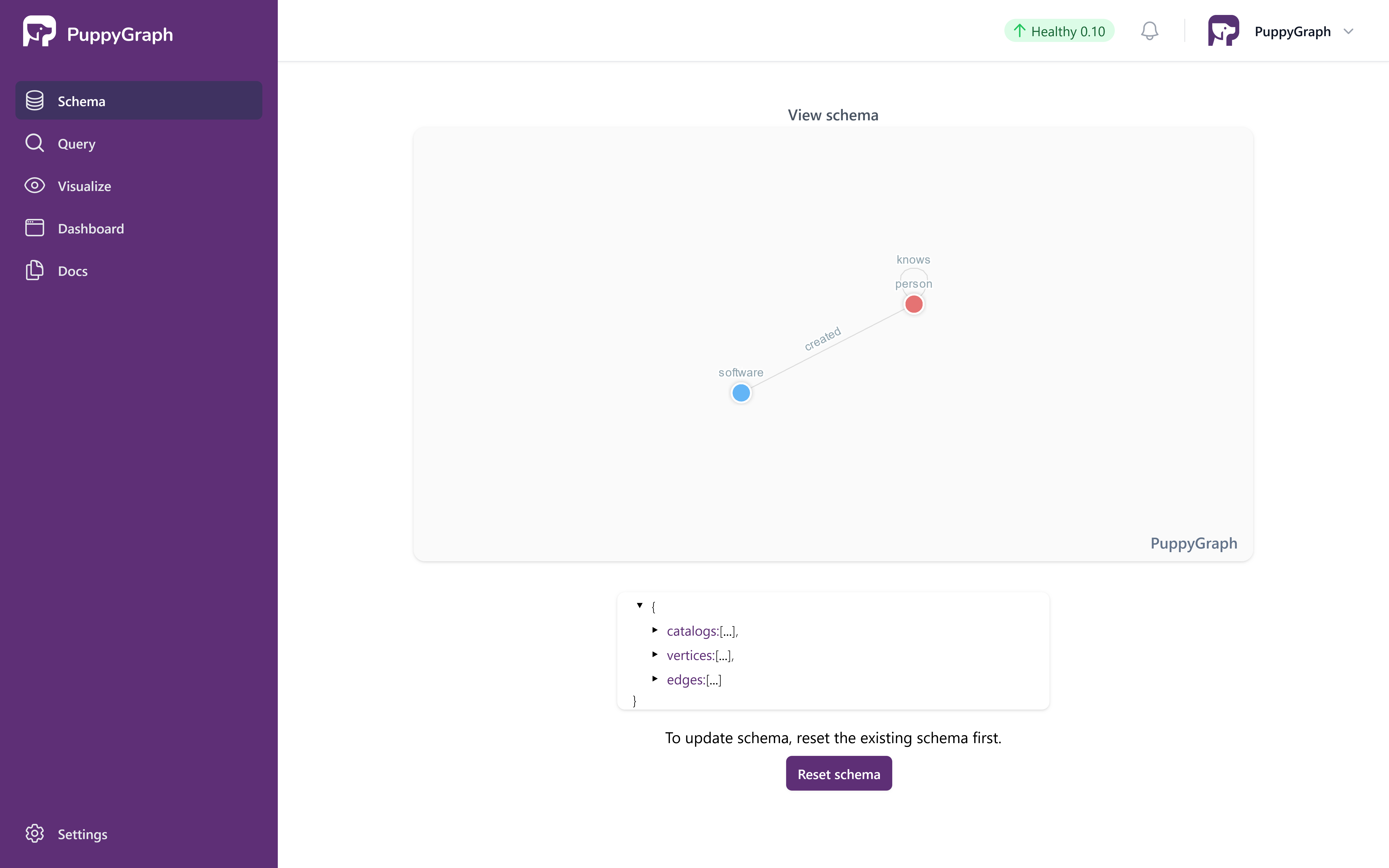
Visualized Schema
Alternative: Schema Uploading via CLI
Alternatively, run the following command to upload the schema file:
curl -XPOST -H "content-type: application/json" --data-binary @./schema.json --user "puppygraph:puppygraph123" localhost:8081/schema
The response shows that graph schema has been uploaded successfully:
Querying the Graph
In this tutorial we will use the Gremlin query language to query the Graph. Gremlin is a graph query language developed by Apache TinkerPop. Prior knowledge of Gremlin is not necessary to follow the tutorial. To learn more about it, visit https://tinkerpop.apache.org/gremlin.html.
Click on the Query panel the left side. The Gremlin Query tab offers an interactive environment for querying the graph using Gremlin.
Interactive Gremlin Query Page
Queries are entered on the left side, and the right side displays the graph visualization.
The first query retrieves the property of the person named "marko".
Copy the following query, paste it in the query input, and click on the run button.
The output is plain text like the following:
Now let's also leverage the visualization. The next query gets all the software created by people known to "marko".
Copy the following query, paste it in the query input, and click on the run button.
The output is as follows. There are two paths in the result as "marko" knows "josh" who created "lop" and "ripple".
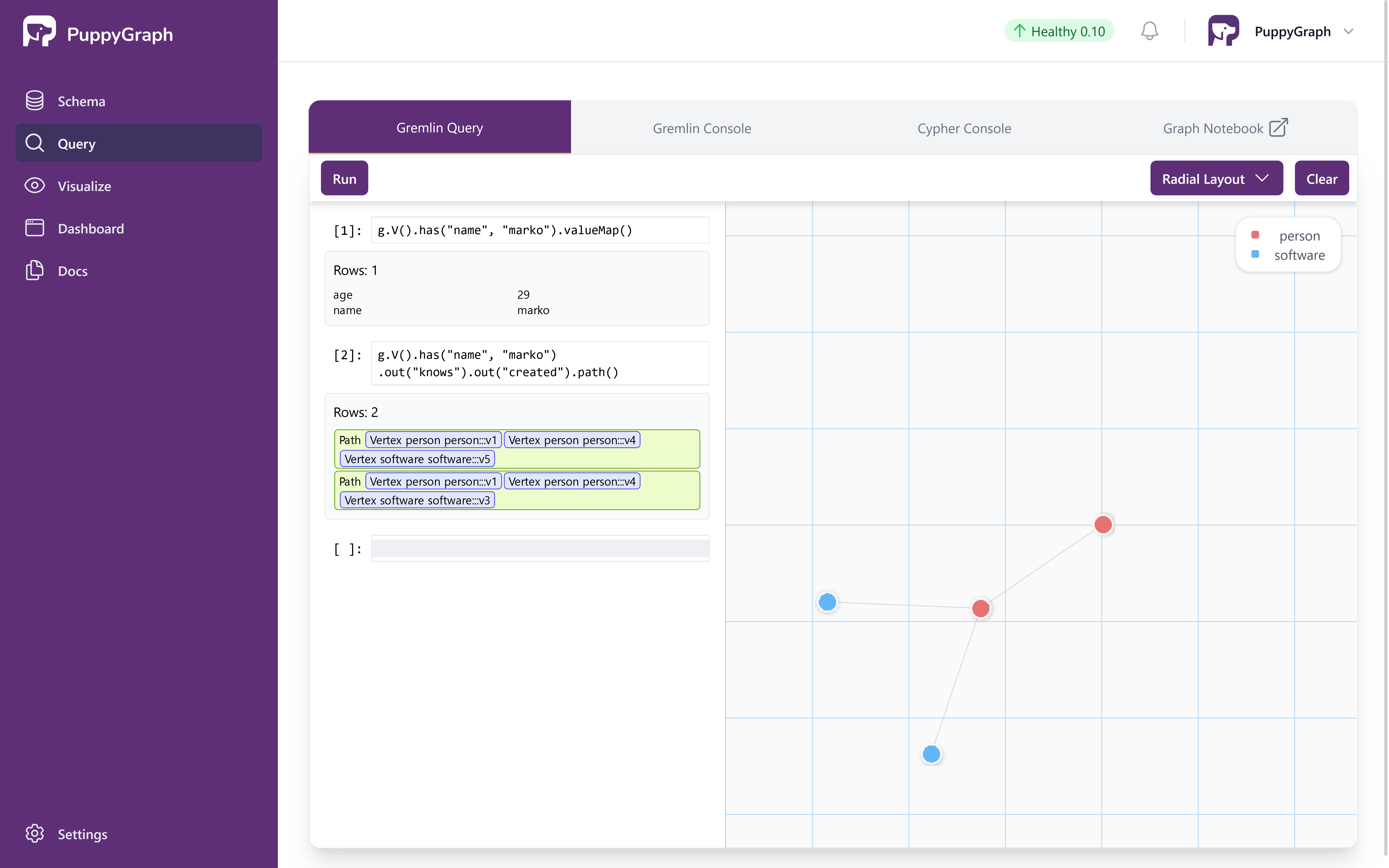
Interactive Query with Results
Alternative: Querying the graph via CLI
Alternatively, we can query the graph via CLI.
Execute the following command to access the PuppyGraph Gremlin Console
The welcome screen appears as follows:
____ ____ _
| _ \ _ _ _ __ _ __ _ _ / ___| _ __ __ _ _ __ | |__
| |_) | | | | | | '_ \ | '_ \ | | | | | | _ | '__| / _` | | '_ \ | '_ \
| __/ | |_| | | |_) | | |_) | | |_| | | |_| | | | | (_| | | |_) | | | | |
|_| \__,_| | .__/ | .__/ \__, | \____| |_| \__,_| | .__/ |_| |_|
|_| |_| |___/ |_|
Welcome to PuppyGraph!
version: 0.10
puppy-gremlin>
Run the following queries in the console to query the Graph.
Properties of the person named "marko":
To exit PuppyGraph Gremlin Console, enter the command:
Cleaning up
Run the following command to shut down and remove the services: