Querying Amazon S3 Tables Data as a Graph
Summary
In this tutorial, you will:
- Create a table bucket on Amazon S3 and load it with example data.
- Start a PuppyGraph Docker container and model the data from the S3 Tables graph as a graph using PuppyGraph.
- Query the data modeled from S3 Tables as a graph.
Prerequisites
It is strongly recommended to take the getting-started tutorial of AWS S3 Tables first to become familiar with AWS S3 Tables and resolve IAM problems. In this demo, we will use a similar approach when creating tables.
Data Preparation
Create a Table Bucket
 Follow step 1 in Tutorial: Getting started with S3 Tables to create a table bucket. We will use Amazon Athena to insert data so please ensure Enable integration is selected.
Follow step 1 in Tutorial: Getting started with S3 Tables to create a table bucket. We will use Amazon Athena to insert data so please ensure Enable integration is selected.
Create Namespace
Use AWS CLI to create a namespace. Replace the placeholders with your actual values.
<table-bucket-arn> is in the format of arn:aws:s3tables:<region>:<account-id>:bucket/<table-bucket-name>.
Create Tables
Use AWS CLI to create tables. Replace the placeholders in corresponded files by your actual value.
aws s3tables create-table --cli-input-json file://table_definition/person_definition.json
aws s3tables create-table --cli-input-json file://table_definition/software_definition.json
aws s3tables create-table --cli-input-json file://table_definition/knows_definition.json
aws s3tables create-table --cli-input-json file://table_definition/created_definition.json
For the table definition files, use the following example definition:
person_definition.json
software_definition.json
knows_definition.json
{
"tableBucketARN": "<table-bucket-arn>",
"namespace": "puppygraph_test",
"name": "knows",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{"name": "id", "type": "string", "required": true},
{"name": "from_id", "type": "string", "required": true},
{"name": "to_id", "type": "string", "required": true},
{"name": "weight", "type": "double"}
]
}
}
}
}
created_definition.json
{
"tableBucketARN": "<table-bucket-arn>",
"namespace": "puppygraph_test",
"name": "created",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{"name": "id", "type": "string", "required": true},
{"name": "fromid", "type": "string", "required": true},
{"name": "to_id", "type": "string", "required": true},
{"name": "weight", "type": "double"}
]
}
}
}
}
Insert Data
Follow step 4 in Tutorial: Getting started with S3 Tables to insert data using Amazon Athena.
INSERT INTO person VALUES
('v1', 'marko', 29),
('v2', 'vadas', 27),
('v4', 'josh', 32),
('v6', 'peter', 35);
INSERT INTO software VALUES
('v3', 'lop', 'java'),
('v5', 'ripple', 'java');
INSERT INTO created VALUES
('e9', 'v1', 'v3', 0.4),
('e10', 'v4', 'v5', 1.0),
('e11', 'v4', 'v3', 0.4),
('e12', 'v6', 'v3', 0.2);
INSERT INTO knows VALUES
('e7', 'v1', 'v2', 0.5),
('e8', 'v1', 'v4', 1.0);
The above SQL creates the following tables:
| id | name | age |
|---|---|---|
| v1 | marko | 29 |
| v2 | vadas | 27 |
| v4 | josh | 32 |
| v6 | peter | 35 |
| id | name | lang |
|---|---|---|
| v3 | lop | java |
| v5 | ripple | java |
| id | from_id | to_id | weight |
|---|---|---|---|
| e7 | v1 | v2 | 0.5 |
| e8 | v1 | v4 | 1.0 |
| id | from_id | to_id | weight |
|---|---|---|---|
| e9 | v1 | v3 | 0.4 |
| e10 | v4 | v5 | 1.0 |
| e11 | v4 | v3 | 0.4 |
| e12 | v6 | v3 | 0.2 |
Deployment
Start a PuppyGraph docker container:
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -d --name puppy --rm --pull=always puppygraph/puppygraph:stable
Log into the PuppyGraph Web UI at http://localhost:8081 with puppygraph as the username and puppygraph123 as the password.
Modeling the Graph
PuppyGraph defines graph modeling by using a schema. There are two method to model the graph:
- Use the graph schema builder to build the schema in Web UI.
- Click on Create graph schema to create a new graph schema.
- Configure the data source.
- Map data to graph step by step.
- Compose a schema JSON file and upload it.
- Replace the placeholders in the file
schema.jsonbelow. - Choose the file and upload it.
- Replace the placeholders in the file
IAM Requirements
The user account configured with the access keys needs to have at least AmazonS3TablesReadOnlyAccess to your S3 tables.
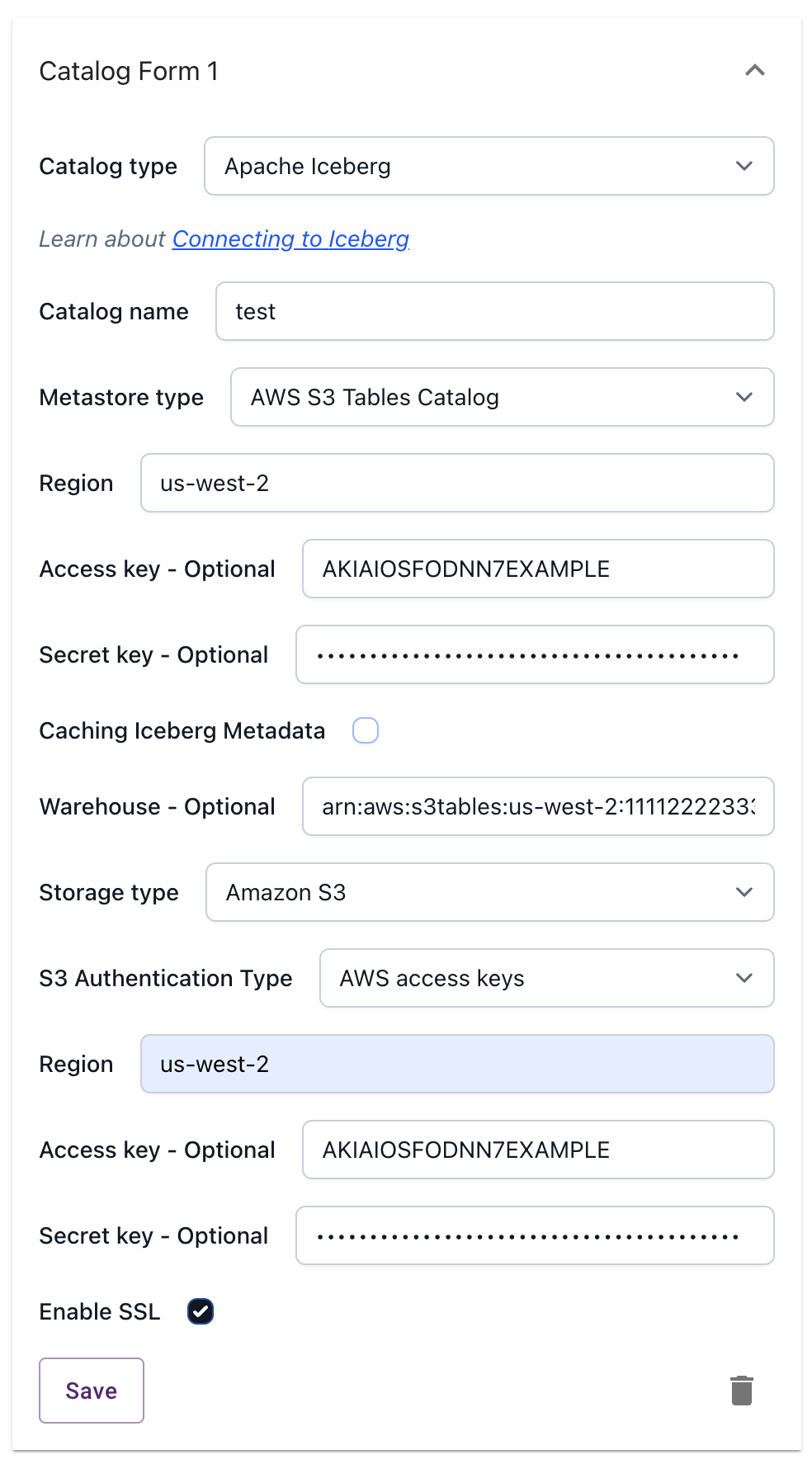
Use your actual Region, Access Key, Secret Key, and Warehouse (table-bucket-arn) values to configure the connection.
schema.json
{
"catalogs": [
{
"name": "test",
"type": "iceberg",
"metastore": {
"type": "s3tables",
"useInstanceProfile": "false",
"region": "<region>",
"accessKey": "<access-key>",
"secretKey": "<secret-key>",
"warehouse": "<table-bucket-arn>",
"enableIcebergMetaCache": "false",
"useDefaultCredentialsProviderChain": "false"
},
"storage": {
"useDefaultCredentialsProviderChain": "false",
"useInstanceProfile": "false",
"region": "<region>",
"accessKey": "<access-key>",
"secretKey": "<secret-key>",
"enableSsl": "true",
"type": "S3"
}
}
],
"graph": {
"vertices": [
{
"label": "person",
"oneToOne": {
"tableSource": {
"catalog": "test",
"schema": "puppygraph_test",
"table": "person"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
},
{
"type": "INT",
"field": "age",
"alias": "age"
}
]
}
},
{
"label": "software",
"oneToOne": {
"tableSource": {
"catalog": "test",
"schema": "puppygraph_test",
"table": "software"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "id_id"
}
]
},
"attributes": [
{
"type": "STRING",
"field": "name",
"alias": "name"
},
{
"type": "STRING",
"field": "lang",
"alias": "lang"
}
]
}
}
],
"edges": [
{
"label": "knows",
"fromVertex": "person",
"toVertex": "person",
"tableSource": {
"catalog": "test",
"schema": "puppygraph_test",
"table": "knows"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "from_id",
"alias": "from_from_id"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "to_id",
"alias": "to_to_id"
}
]
},
"attributes": [
{
"type": "DOUBLE",
"field": "weight",
"alias": "weight"
}
]
},
{
"label": "created",
"fromVertex": "person",
"toVertex": "software",
"tableSource": {
"catalog": "test",
"schema": "puppygraph_test",
"table": "created"
},
"id": {
"fields": [
{
"type": "STRING",
"field": "id",
"alias": "id_id"
}
]
},
"fromId": {
"fields": [
{
"type": "STRING",
"field": "fromid",
"alias": "from_fromid"
}
]
},
"toId": {
"fields": [
{
"type": "STRING",
"field": "to_id",
"alias": "to_to_id"
}
]
},
"attributes": [
{
"type": "DOUBLE",
"field": "weight",
"alias": "weight"
}
]
}
]
}
}
Query the Graph
Navigate to Query in the Web UI. Use Graph Query for Gremlin/openCypher queries with visualization.
Example Queries
-
Retrieve an vertex named 'marko'.
Gremlin:
openCypher:
-
Retrieve the paths from "marko" to the software created by those whom "marko" knows.
Gremlin:
openCypher:
Cleanup
To stop and remove the PuppyGraph Docker container, run:
To delete the created tables, namespace, and bucket, use the aws cli commands:
# Delete the tables
aws s3tables delete-table \
--region <region> \
--table-bucket-arn <table-bucket-arn> \
--namespace puppygraph_test \
--table-name person
aws s3tables delete-table \
--region <region> \
--table-bucket-arn <table-bucket-arn> \
--namespace puppygraph_test \
--table-name software
aws s3tables delete-table \
--region <region> \
--table-bucket-arn <table-bucket-arn> \
--namespace puppygraph_test \
--table-name knows
aws s3tables delete-table \
--region <region> \
--table-bucket-arn <table-bucket-arn> \
--namespace puppygraph_test \
--table-name created
# Delete the namespace
aws s3tables delete-namespace \
--region <region> \
--table-bucket-arn <table-bucket-arn> \
--namespace puppygraph_test
# Delete the table bucket
aws s3tables delete-table-bucket \
--region <region> \
--table-bucket-arn <table-bucket-arn>