Querying Snowflake Open Catalog Data as a Graph
Summary
In this tutorial, you will:
- Create a Snowflake Open Catalog and import data into it;
- Start a PuppyGraph Docker container and query the data as a graph.
Prerequisites
Docker
Please ensure that docker is available.
Docker is required to run the PuppyGraph server. You can download Docker from here.
The installation can be verified by running:
PySpark
Please ensure that pyspark is available. You can install it from here.
Snowflake Account
In this tutorial, we will use a Snowflake account to create an Open Catalog and import data into it. You can find more information on Snowflake's website.
Open Catalog and Data Preparation
In order to query data as a graph, we need to import data into Snowflake Open Catalog.
Note
Preparation steps are adapted from the Snowflake Open Catalog Documentation.
Create a Snowflake Open Catalog account by using Snowflake SQL
Note
This step is adapted from the Snowflake Open Catalog Documentation: Creating an Account.
- Sign in to Snowsight using admin account.
-
Open a SQL Worksheet, run the CREATE ACCOUNT SQL command:
USE ROLE ORGADMIN; CREATE ACCOUNT <account_name> ADMIN_NAME = <user_name> ADMIN_PASSWORD = '<user_password>' MUST_CHANGE_PASSWORD = FALSE EMAIL = '<user_email>' EDITION = standard REGION = <cloud_region> POLARIS = TRUE;Parameter Value account_name Specifies the identifier (i.e. name) for the account. user_name Login name of the initial administrative user of the account. user_password Password for the initial administrative user of the account. user_email Email address of the initial administrative user of the account. This email address is used to send any notifications about the account. cloud_region The region where you want to store Iceberg tables. It is same as your S3 storage bucket; for example: AWS_US_EAST_1 -
Copy the accountLocatorUrl in the command output and save it for signing in to Open Catalog.
Create a Open Catalog using Amazon Simple Storage Service (Amazon S3)
Note
This step is adapted from the Snowflake Open Catalog Documentation: Creating a catalog.
Step 1: Create an Amazon S3 bucket
- Sign in to the AWS Management Console.
- On the home dashboard, search for and select S3.
- Select Create bucket.
- For Bucket name, enter a name for the bucket.
- Configure the settings for your storage bucket or use the default settings.
- Select Create bucket.
- Search for and select the storage bucket you created.
- To create a folder, select Create folder.
- For Folder name, enter the name of the folder where you want to store Apache Iceberg tables, and then select Create folder.
- Select the folder you created.
- Select Copy S3 URI, and then store the URI for later use.
Step 2: Create an IAM policy that grants access to your S3 location
- Sign in to the AWS Management Console.
- On the home dashboard, select IAM.
- In the navigation pane, select Account settings.
- Under Security Token Service (STS), in the Endpoints list, find the Open Catalog region where your account is located, and if the STS status is inactive, set the toggle to Active.
- In the navigation pane, select Policies.
- Select Create Policy.
- For Policy editor, select JSON.
-
Add a policy to provide Open Catalog with the required permissions to read and write data to your S3 location.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::<my_bucket>/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "arn:aws:s3:::<my_bucket>", "Condition": { "StringLike": { "s3:prefix": [ "*" ] } } } ] }Parameter Value my_bucket your actual bucket name; for example, puppygraph-test/snowflake. -
Select Next.
- For Policy name, enter a policy name (for example, open_catalog_access).
- Optional: For Description, enter a description.
- Select Create policy.
Step 3: Create an IAM role to grant privileges on your S3 bucket
- From the AWS Management Console, on the Identity and Access Management (IAM) Dashboard, in the navigation pane, select Roles.
- Select Create role.
- For the trusted entity type, select AWS account.
- Under An AWS account, select This account.
In a later step, you modify the trusted relationship and grant access to Open Catalog. - Select Next.
- Select the policy that you created in the previous step, and then select Next.
- Enter a role name and description for the role, and then select Create role.
You have now created an IAM policy for an S3 location, created an IAM role, and attached the policy to the role. - To view the role summary page, select View role.
- Locate and record the ARN (Amazon Resource Name) value for the role.
Step 4: Create a catalog in Open Catalog
- Sign in to Open Catalog.
- On the Open Catalog home page, in the Catalogs area, select + Create.
-
In the Create Catalog dialog, complete the fields and select Create.
field Value Name Enter a name for the catalog. External Keep the External toggle to Off. Storage Provider Select S3. Default base location Enter the default base location for your AWS S3 storage bucket; for example, s3://puppygraph-test/snowflake/ S3 role ARN Enter the ARN of the IAM role that you created for Open Catalog.
Step 5: Retrieve the AWS IAM user for your Open Catalog account
- On the Open Catalog home page, in the Catalogs area, select the catalog that you created.
- Under Storage Details, copy the External ID and IAM user arn.
Step 6: Grant the IAM user permissions to access bucket objects
- Sign in to the AWS Management Console.
- On the home dashboard, search for and select IAM.
- In the navigation pane, select Roles.
- Select the IAM role that you created for your storage configuration.
- Select the Trust relationships tab.
- Select Edit trust policy.
-
Modify the policy document with the catalog storage details that you recorded, and select Update policy.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "AWS": "<open_catalog_user_arn>" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": "<open_catalog_external_id>" } } } ] }Parameter Value open_catalog_user_arn the IAM user ARN that you recorded open_catalog_external_id ExternalId with the value that you recorded.
Step 7: Create a catalog role, a principal role, a namespace
- Sign in to Open Catalog.
- From the menu on the left, select Connections.
- Select the Roles tab.
- Select + Principal role.
- Enter a name for the principal role, and then select Create.
- From the menu on the left, select Catalogs.
- From the list of catalogs, select the catalog for which you want to create a catalog role.
- Select the Roles tab.
- Select + Catalog role.
- Enter a name for the Catalog role, select all of privileges, and then select Create.
- Select Grant to Principal role, grant the role to the principal role.
- Select + Namespace.
- Enter a Namespace name and then select Create.
- Select the namespace you created and select + Privilege.
- Select a Catalog Role, select all privileges and then select Grant privileges.
Step 8: Configure a service connection
- Sign in to Open Catalog.
- In the menu on the left, select Connections.
- Select + Connection.
-
In the Configure Service Connection dialog, complete the fields.
field Value Name Enter a service principal name. Query Engine Enter a query engine name for the service connection. Principal Role Select a principal role. -
Select Create. The Client ID and Client Secret service credentials for the service principal are created.
-
In the Configure Service Connection dialog, save the service credentials.
1) To copy the Client ID, select Copy client id inside the Client ID field, and paste it in a file.
2) To copy the Client Secret, select Copy secret inside the Client Secret field, and paste it in a file.- Important
You must save the service credentials before you close the Configure Service Connection window, because you can’t retrieve them later.
- Important
-
Select Close.
Creating tables in Open Catalog
Note
This step is adapted from the Snowflake Open Catalog Documentation: Register a service connection.
We can import data to Snowflake open catalog by pyspark
from pyspark.sql import SparkSession
# Create Spark session and add AWS-related dependencies, including KMS
spark = SparkSession.builder.appName('iceberg_lab') \
.config('spark.jars.packages', (
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,'
'org.apache.iceberg:iceberg-gcp-bundle:1.5.2,'
'software.amazon.awssdk:s3:2.17.260,'
'software.amazon.awssdk:sts:2.17.260,'
'software.amazon.awssdk:dynamodb:2.17.260,'
'software.amazon.awssdk:glue:2.17.260,'
'software.amazon.awssdk:kms:2.17.260'
)) \
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') \
.config('spark.sql.defaultCatalog', 'opencatalog') \
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.opencatalog.type', 'rest') \
.config('spark.sql.catalog.opencatalog.uri', 'https://<open_catalog_account_identifier>.snowflakecomputing.com/polaris/api/catalog') \
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation', 'vended-credentials') \
.config('spark.sql.catalog.opencatalog.credential', '<client_id>:<client_secret>') \
.config('spark.sql.catalog.opencatalog.warehouse', '<catalog_name>') \
.config('spark.sql.catalog.opencatalog.scope', 'PRINCIPAL_ROLE:<principal_role_name>') \
.getOrCreate()
try:
# Create 'person' table and insert data
spark.sql("""
CREATE TABLE IF NOT EXISTS opencatalog.test_ns1.person (
id STRING,
name STRING,
age INT
)
""")
spark.sql("""
INSERT INTO opencatalog.test_ns1.person (id, Name, age) VALUES
('v1', 'marko', 29),
('v2', 'vadas', 27),
('v4', 'josh', 32),
('v6', 'peter', 35)
""")
# Create 'Software' table and insert data
spark.sql("""
CREATE TABLE IF NOT EXISTS opencatalog.test_ns1.software (
id STRING,
name STRING,
LANG STRING
)
""")
spark.sql("""
INSERT INTO opencatalog.test_ns1.software (id, name, LANG) VALUES
('v3', 'lop', 'java'),
('v5', 'ripple', 'java')
""")
# Create 'created' table and insert data
spark.sql("""
CREATE TABLE IF NOT EXISTS opencatalog.test_ns1.created (
id STRING,
from_id STRING,
to_id STRING,
weight DOUBLE
)
""")
spark.sql("""
INSERT INTO opencatalog.test_ns1.created (id, from_id, to_id, weight) VALUES
('e9', 'v1', 'v3', 0.4),
('e10', 'v4', 'v5', 1.0),
('e11', 'v4', 'v3', 0.4),
('e12', 'v6', 'v3', 0.2)
""")
# Create 'knows' table and insert data
spark.sql("""
CREATE TABLE IF NOT EXISTS opencatalog.test_ns1.knows (
id STRING,
from_id STRING,
to_id STRING,
weight DOUBLE
)
""")
spark.sql("""
INSERT INTO opencatalog.test_ns1.knows (id, from_id, to_id, weight) VALUES
('e7', 'v1', 'v2', 0.5),
('e8', 'v1', 'v4', 1.0)
""")
# Show inserted data from each table
print("Data in 'person' table:")
spark.sql("SELECT * FROM opencatalog.test_ns1.person").show()
print("Data in 'software' table:")
spark.sql("SELECT * FROM opencatalog.test_ns1.software").show()
print("Data in 'created' table:")
spark.sql("SELECT * FROM opencatalog.test_ns1.created").show()
print("Data in 'knows' table:")
spark.sql("SELECT * FROM opencatalog.test_ns1.knows").show()
except Exception as e:
print(f"An error occurred: {e}")
finally:
# Stop Spark session
spark.stop()
| Parameter | Value |
|---|---|
| open_catalog_account_identifier | Specifies the account identifier for your Open Catalog account; for example: abc24777.us-east-1 |
| client_id | Specifies the client ID for the service principal to use. |
| client_secret | Specifies the client secret for the service principal to use. |
| catalog_name | Specifies the name of the catalog to connect to. |
| principal_role_name | Specifies the principal role that is granted to the service principal. |
Starting PuppyGraph
 Start the PuppyGraph server with the following command.
Start the PuppyGraph server with the following command.
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -e PUPPYGRAPH_PASSWORD=puppygraph123 --name puppy --rm -itd puppygraph/puppygraph:stable
Modeling the Graph
Step 1: Connecting to the Open Catalog
Login onto PuppyGraph with puppygraph as the username and puppygraph123 as the password.
Click on Create graph schema to create a new graph schema.
Fill in the fields as follows.
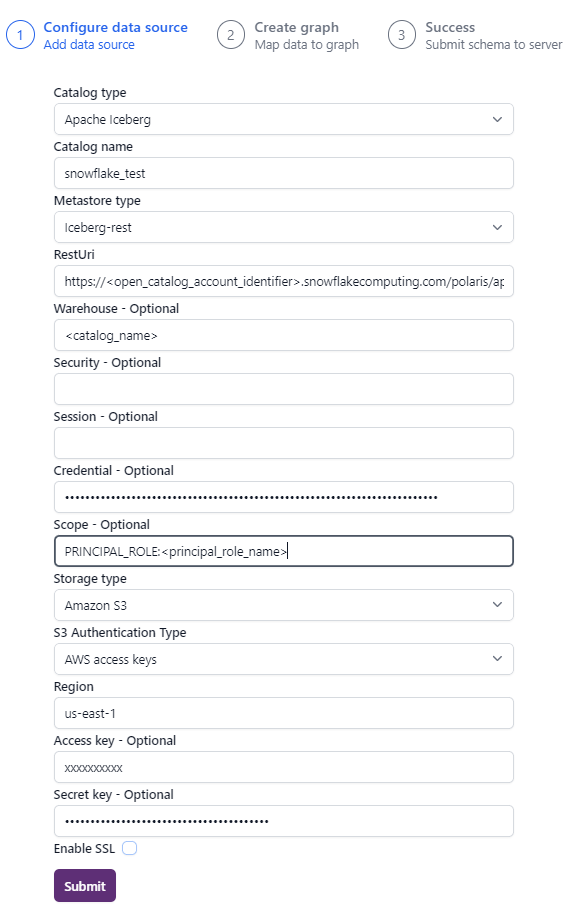
| Parameter | Value |
|---|---|
| Catalog type | Apache Iceberg |
| Catalog name | Some name for the catalog as you like. |
| Metastore Type | Iceberg REST |
| RestUri | Same as pyspark; for example: https://abc24777.us-east-1.snowflakecomputing.com/polaris/api/catalog. |
| Warehouse | Specifies the name of the catalog to connect to. |
| Credential | Same as pyspark, client_id:client_secret |
| Scope | Same as pyspark, PRINCIPAL_ROLE:principal_role_name |
| Storage type | Amazon S3 |
| S3 Authentication Type | AWS access keys |
| Region | The region of your S3 storage bucket; For example: us-east-1 |
| Access key | Your Access Key |
| Secret key | Your Secret Key |
Click on Submit to connect to the Open Catalog.
Step 2: Building the Graph Schema
In the Schema Builder, select the modern database and add the first node type to the graph from the table person.
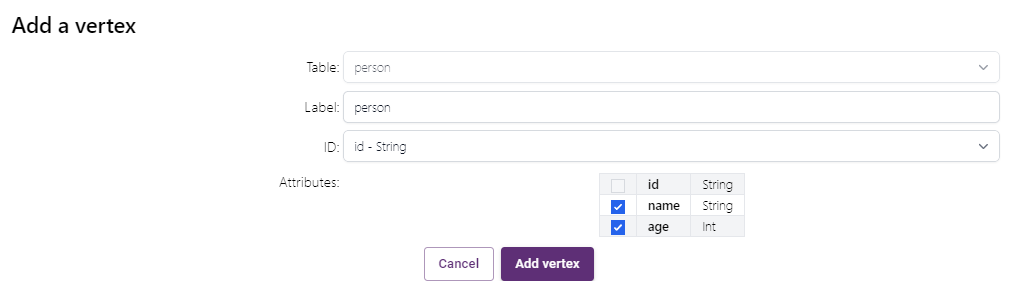
After that use the Auto Suggestion to create other nodes and edges.
Select person as the start node (vertex) and add the auto suggested nodes and edges.
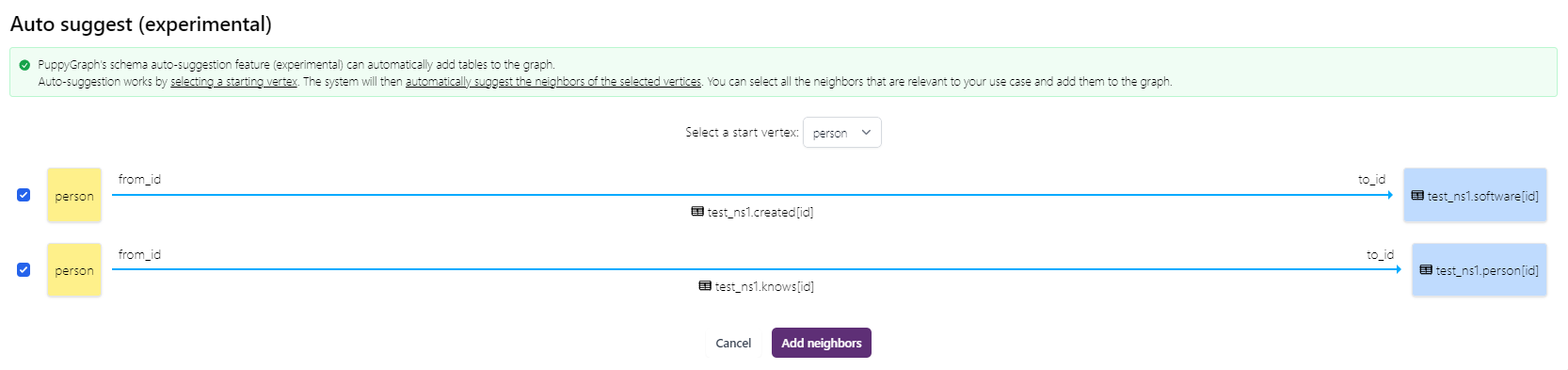
The graph schema should look like this:
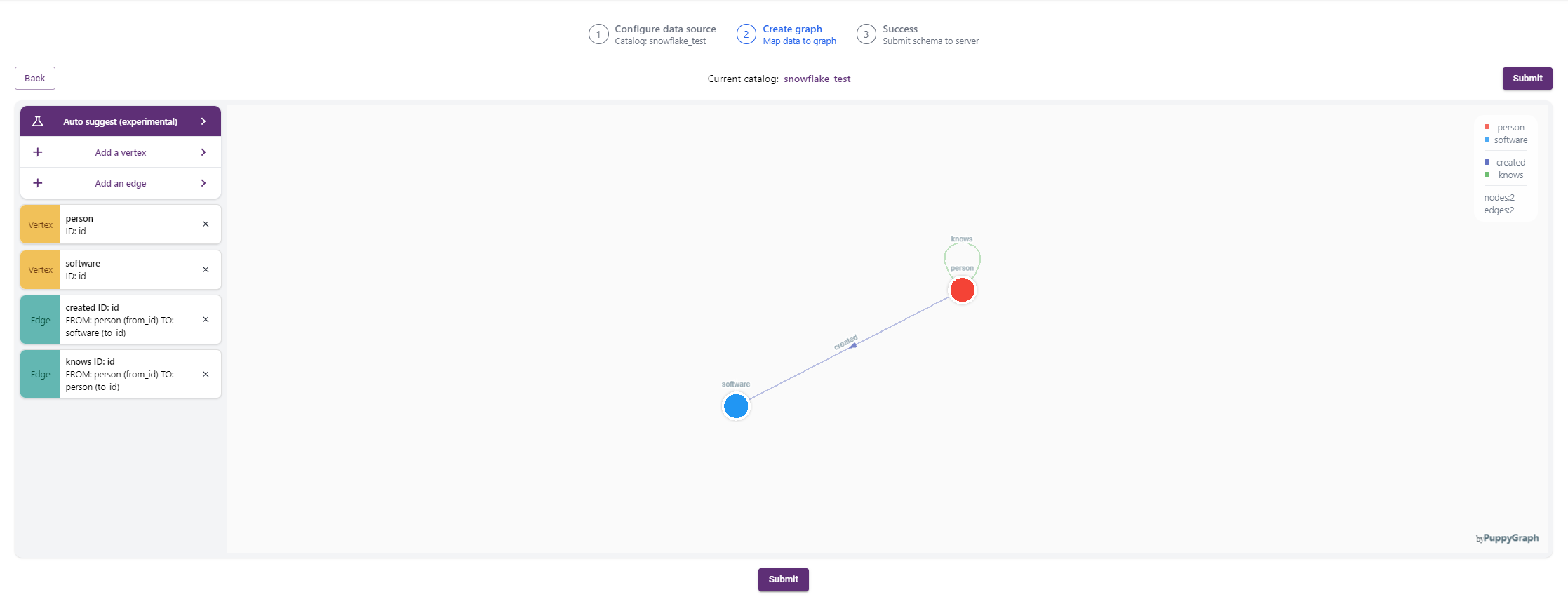 Submit the schema to create the graph.
Submit the schema to create the graph.
Step 3: Querying the Graph
PuppyGraph provides a Dashboard that gives the summary of the graph.
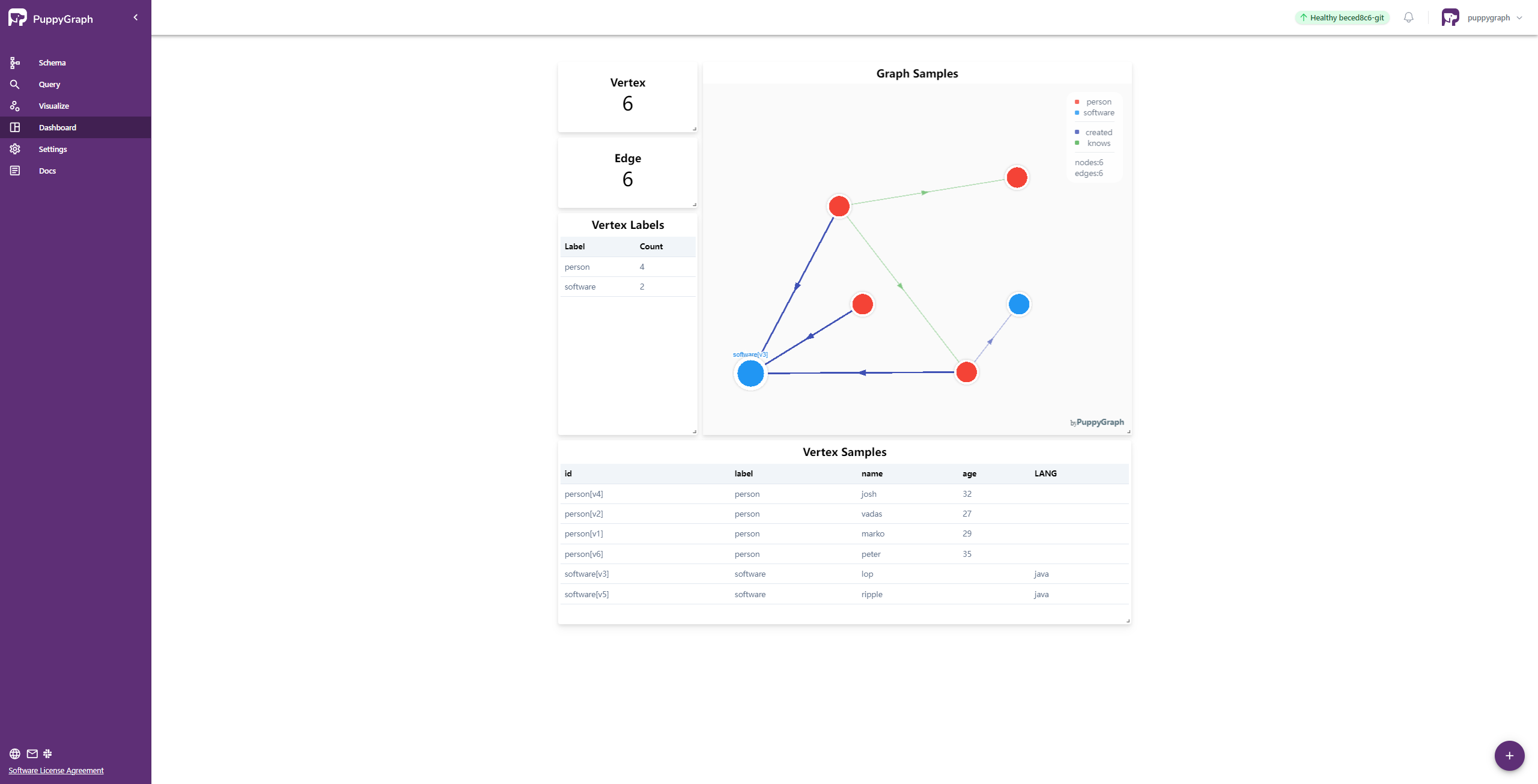
One can also use the Interactive Query UI to further explore the graph by sending queries.
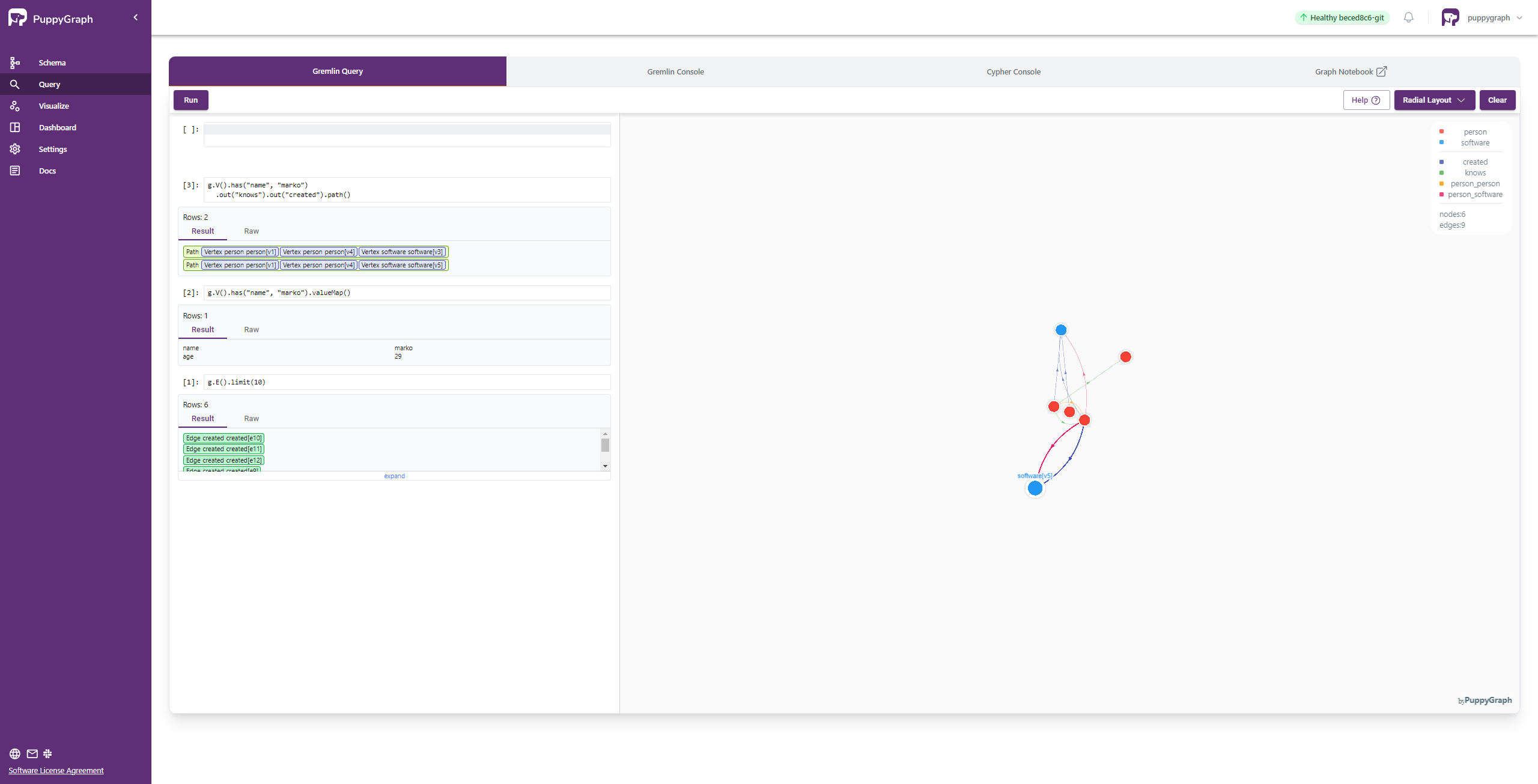
Cleaning up
Run the following command to shut down and remove the PuppyGraph