Querying ClickHouse Data as a Graph
Summary
In this tutorial, you will:
- Start a PuppyGraph container alongside a ClickHouse container and load example data.
- Connect ClickHouse to PuppyGraph and define a graph schema.
- Run Cypher and Gremlin queries against the ClickHouse data as a graph.
Self-contained ClickHouse Data
This tutorial bundles a ClickHouse container and seeds it with the TinkerPop modern graph sample data.
In real deployments, PuppyGraph queries your existing ClickHouse databases directly. See Connecting to ClickHouse for the connection reference.
Prerequisites
Please ensure that docker compose is available. The installation can be verified by running:
See https://docs.docker.com/compose/install/ for Docker Compose installation instructions and https://www.docker.com/get-started/ for more details on Docker.
Accessing the PuppyGraph Web UI requires a browser. The schema upload and query steps also have CLI alternatives via curl and the bundled Gremlin console.
Setup
Deployment
 Create a file
Create a file docker-compose.yaml with the following content:
docker-compose.yaml
version: "3"
services:
puppygraph:
image: puppygraph/puppygraph:latest
pull_policy: always
container_name: puppygraph
environment:
- PUPPYGRAPH_USERNAME=puppygraph
- PUPPYGRAPH_PASSWORD=puppygraph123
networks:
- ch_net
ports:
- "8081:8081"
- "8182:8182"
- "7687:7687"
clickhouse-server:
image: clickhouse/clickhouse-server:latest
container_name: clickhouse-server
environment:
- CLICKHOUSE_USER=ch_user
- CLICKHOUSE_PASSWORD=ch_pwd
networks:
- ch_net
ports:
- "8123:8123"
- "9000:9000"
- "9004:9004"
networks:
ch_net:
name: puppy-ch
Default passwords
The compose file ships with default credentials for convenience. Change CLICKHOUSE_USER and CLICKHOUSE_PASSWORD before running on a publicly accessible machine.
Start the stack:
[+] Running 3/3
✔ Network puppy-ch Created 0.1s
✔ Container clickhouse-server Started 0.6s
✔ Container puppygraph Started 0.7s
Data Preparation
Open a clickhouse-client shell:
Paste the following SQL into the prompt to create the database and insert data:
modern.sql
CREATE DATABASE IF NOT EXISTS modern;
CREATE TABLE modern.software (
id String,
name String,
lang String
) ENGINE = MergeTree() ORDER BY id;
INSERT INTO modern.software VALUES ('v3', 'lop', 'java'), ('v5', 'ripple', 'java');
CREATE TABLE modern.person (
id String,
name String,
age Int32
) ENGINE = MergeTree() ORDER BY id;
INSERT INTO modern.person VALUES
('v1', 'marko', 29),
('v2', 'vadas', 27),
('v4', 'josh', 32),
('v6', 'peter', 35);
CREATE TABLE modern.created (
id String,
from_id String,
to_id String,
weight Float64
) ENGINE = MergeTree() ORDER BY id;
INSERT INTO modern.created VALUES
('e9', 'v1', 'v3', 0.4),
('e10', 'v4', 'v5', 1.0),
('e11', 'v4', 'v3', 0.4),
('e12', 'v6', 'v3', 0.2);
CREATE TABLE modern.knows (
id String,
from_id String,
to_id String,
weight Float64
) ENGINE = MergeTree() ORDER BY id;
INSERT INTO modern.knows VALUES
('e7', 'v1', 'v2', 0.5),
('e8', 'v1', 'v4', 1.0);
The above creates four tables under the modern database. ClickHouse uses native types String, Int32, and Float64; the graph schema below maps them to PuppyGraph's STRING, INT, and DOUBLE.
| id | name | age |
|---|---|---|
| v1 | marko | 29 |
| v2 | vadas | 27 |
| v4 | josh | 32 |
| v6 | peter | 35 |
| id | name | lang |
|---|---|---|
| v3 | lop | java |
| v5 | ripple | java |
| id | from_id | to_id | weight |
|---|---|---|---|
| e9 | v1 | v3 | 0.4 |
| e10 | v4 | v5 | 1.0 |
| e11 | v4 | v3 | 0.4 |
| e12 | v6 | v3 | 0.2 |
| id | from_id | to_id | weight |
|---|---|---|---|
| e7 | v1 | v2 | 0.5 |
| e8 | v1 | v4 | 1.0 |
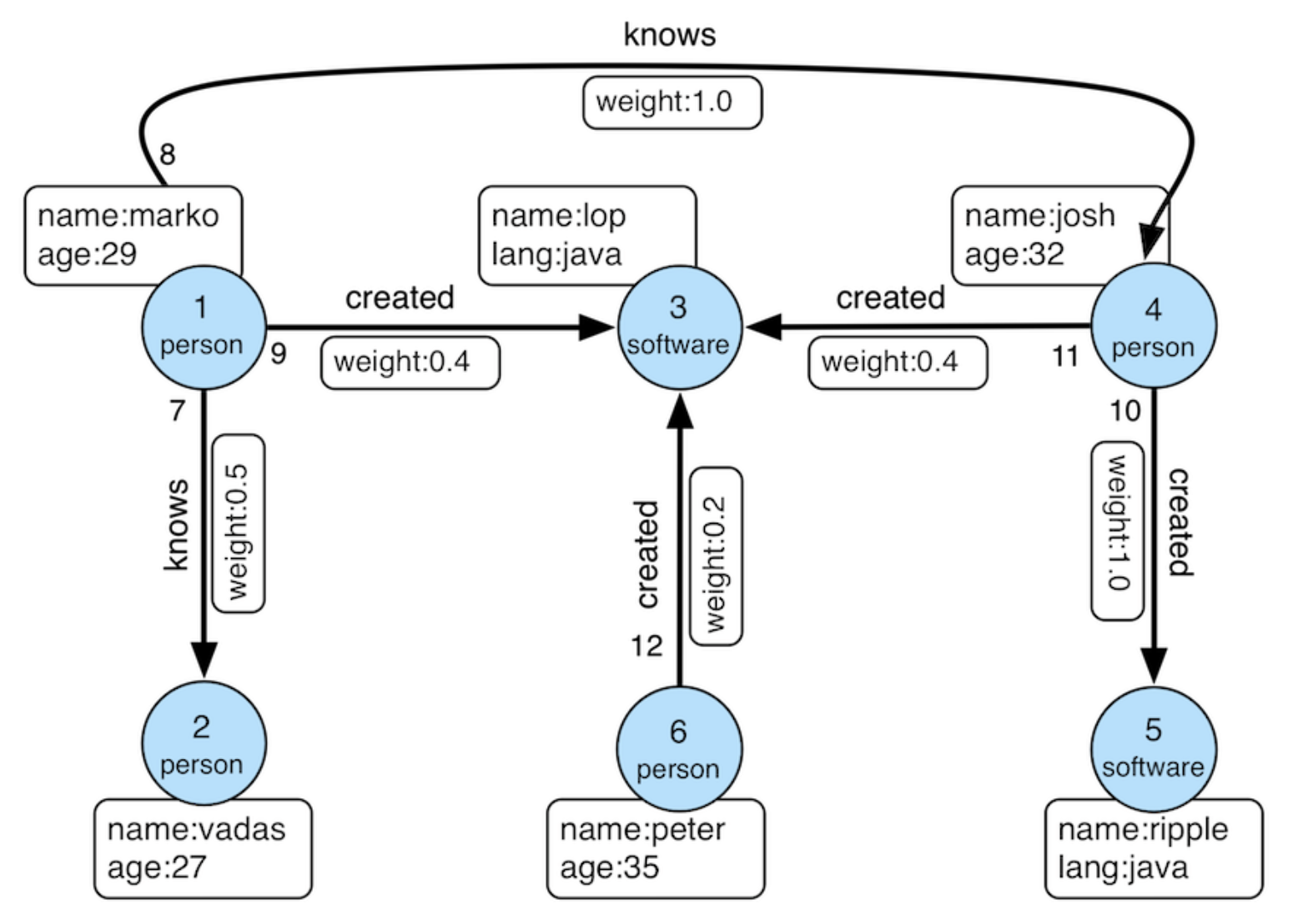
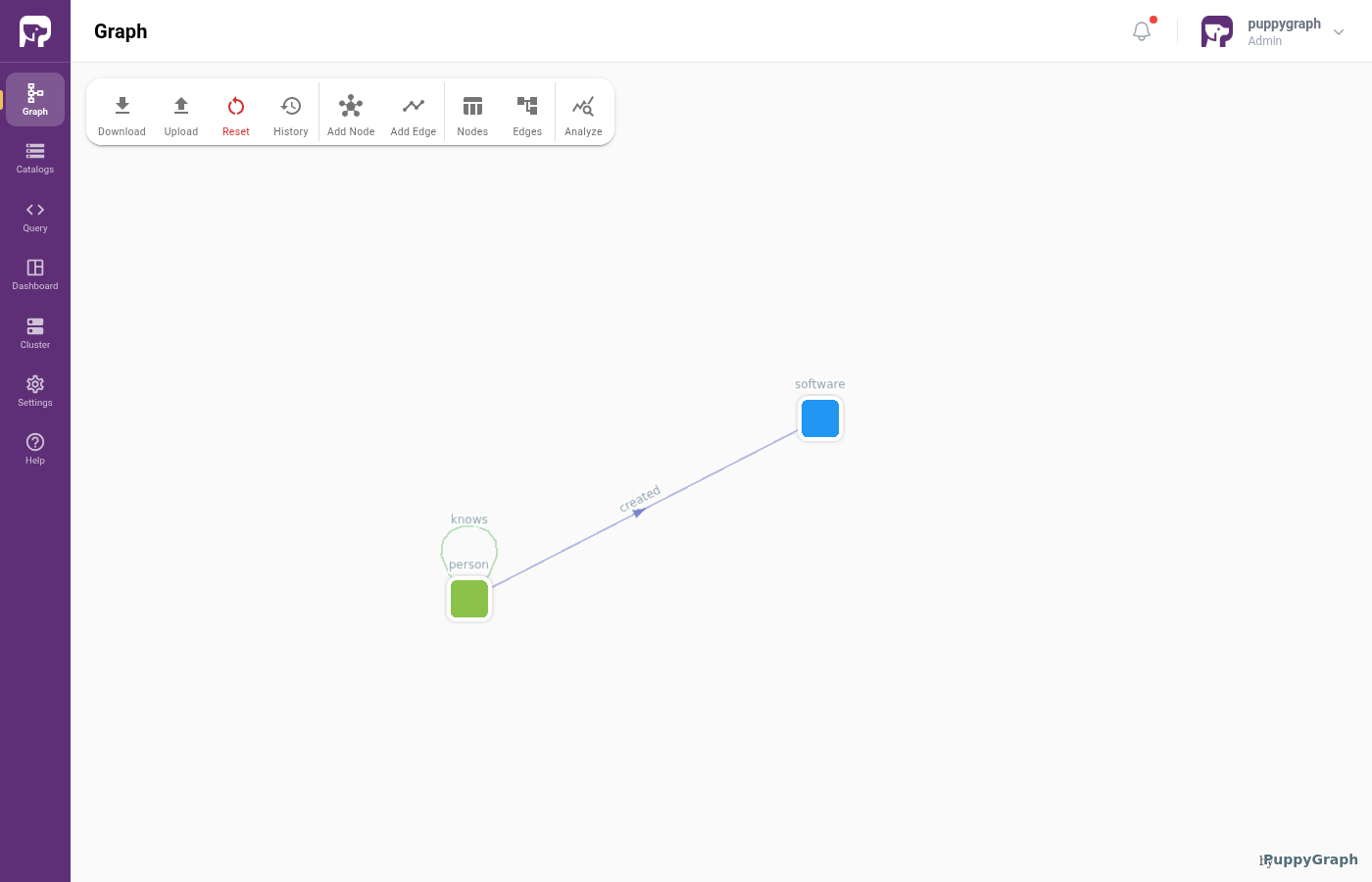
Modeling a Graph
We model the data as the TinkerPop modern graph: two node types (person, software) and two edge types (knows, created).
First, log into the PuppyGraph Web UI at http://localhost:8081 with the credentials configured above:
| Field | Value |
|---|---|
| Username | puppygraph |
| Password | puppygraph123 |
There are two ways to define the schema in PuppyGraph: build it interactively in the Schema Builder, or upload a JSON file directly. Pick whichever you prefer; both produce the same graph.
Build the graph in the Schema Builder
The Schema Builder is the visual editor in the PuppyGraph Web UI for adding catalogs, nodes, and edges step by step. It's the recommended path when you're modeling a graph for the first time or want to inspect what each click produces. For a deeper visual walkthrough of every dialog and field, see Modeling a Graph through the Schema Builder. The summary below covers what's needed to build the modern graph against this tutorial's ClickHouse data.
Connecting to ClickHouse
Click Create Catalog, then expand OLAP & Analytics and pick ClickHouse.
Fill in the connection form:
| Field | Value |
|---|---|
| Catalog name | clickhouse_data |
| Username | ch_user |
| Password | ch_pwd |
| JDBC Connection String | jdbc:ch://clickhouse-server:8123 |
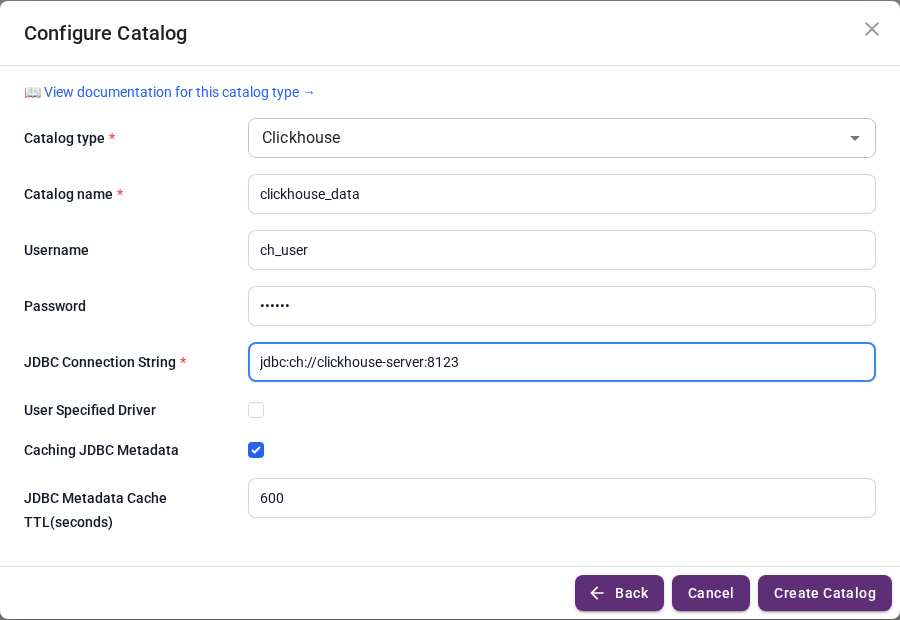
Click Create Catalog.
Adding nodes
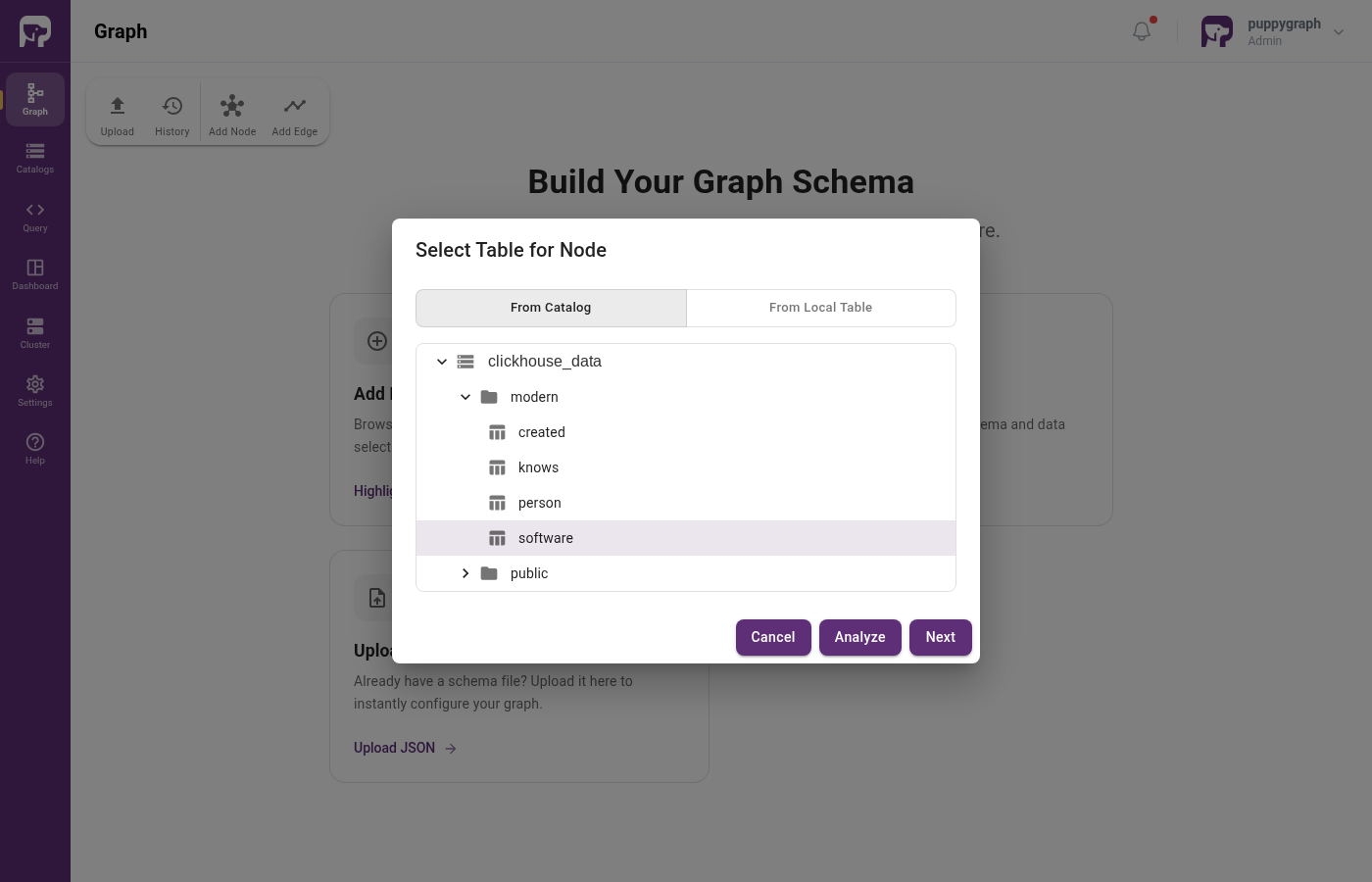
Click Add Node in the toolbar. The Select Table for Node dialog opens. Expand clickhouse_data then modern, pick software, then click Next.
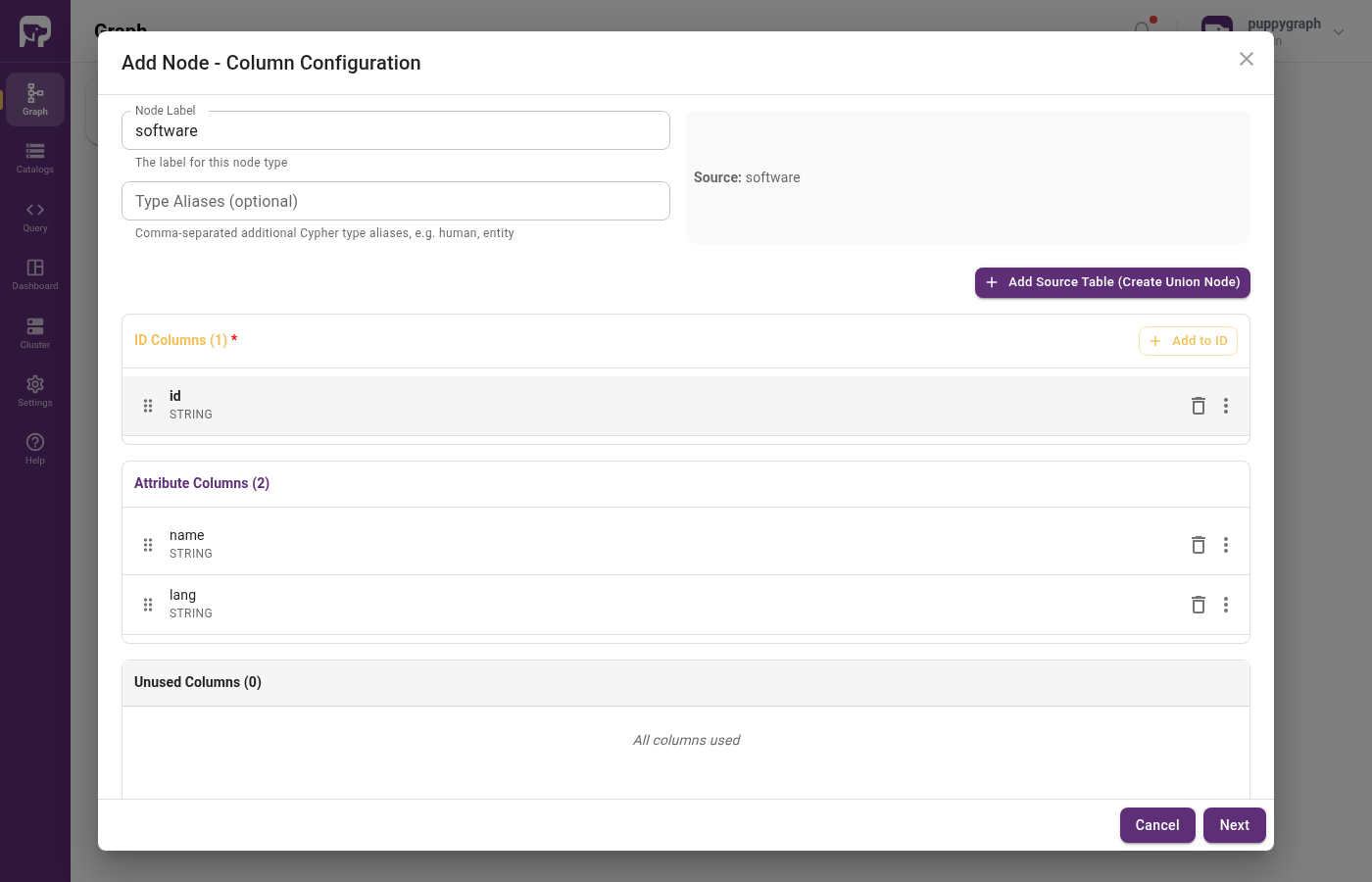
In the Add Node wizard, click Add to ID and select id from the dropdown. The wizard moves id into ID Columns, leaving name and lang as attributes. Click Next, leave Enable Local Replication off, then click Add Node.
Repeat for person. The flow is the same: click Add Node, pick the table, click Next, assign id to ID Columns, leave replication off, click Add Node.
Adding edges
Click Add Edge in the toolbar, pick created from the catalog tree, then click Next.
In the Add Edge wizard, set:
| Field | Value |
|---|---|
| From Node | person |
| To Node | software |
FROM Select Column |
from_id |
TO Select Column |
to_id |
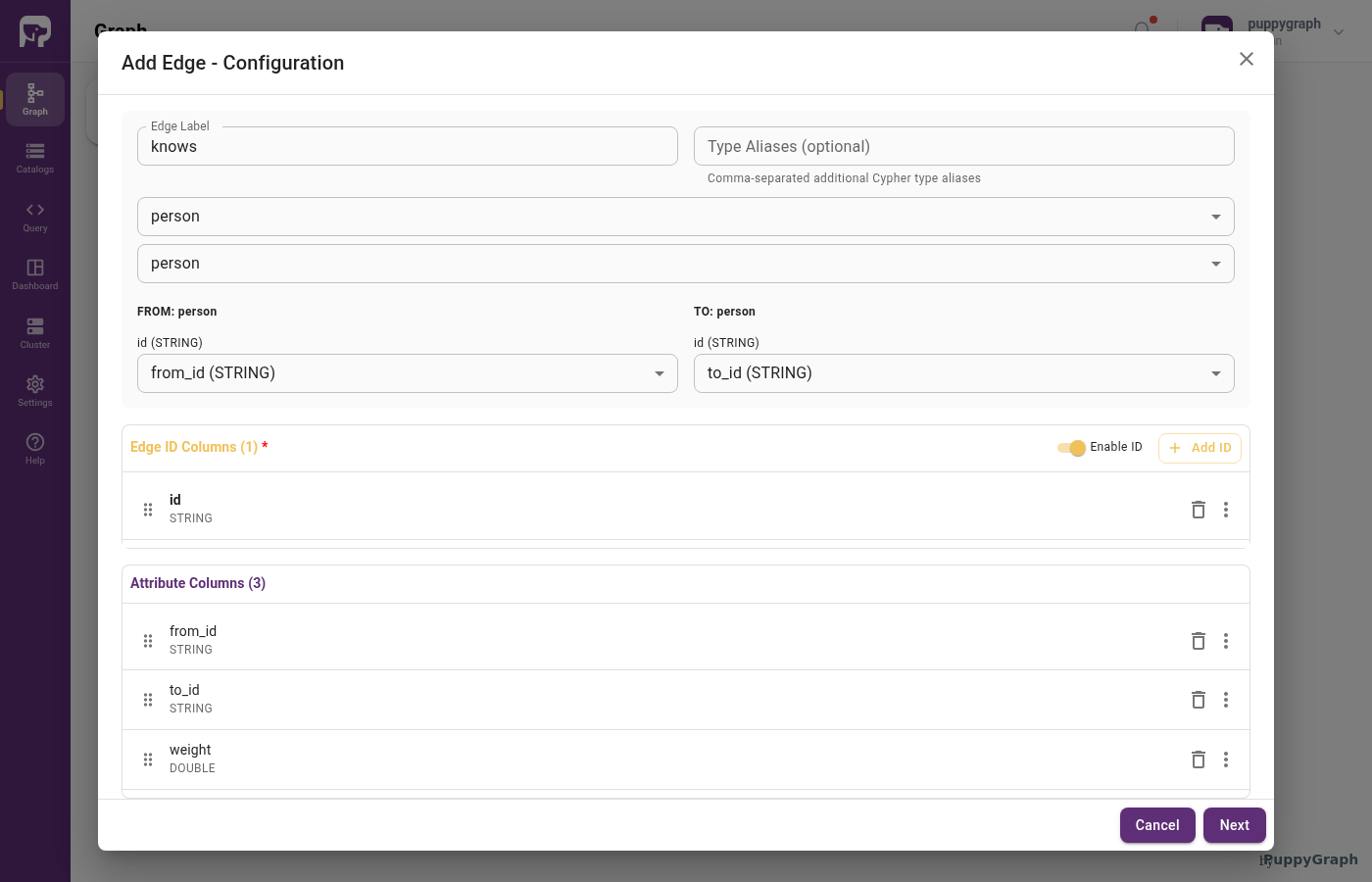
Click Add to ID and select id to set the edge identifier. Click Next, leave Enable Local Replication off, then click Add Edge.
Repeat for knows with both From Node and To Node set to person. The other settings are identical to created.
Upload a schema file
If you've already built the graph in the Schema Builder above, you can skip this section. The resulting schema is the same.
This method writes the full schema to a JSON file and uploads it directly. It's useful when you already have a schema for an environment and want to recreate it elsewhere (e.g. for CI, scripted setup, or copy-pasting between PuppyGraph instances).
Create a file schema.json with the following content:
schema.json
{
"catalog": [
{
"name": "clickhouse_data",
"type": "clickhouse",
"jdbc": {
"username": "ch_user",
"password": "ch_pwd",
"jdbcUri": "jdbc:ch://clickhouse-server:8123"
}
}
],
"node": [
{
"label": "software",
"dataSourceGroup": {
"externalDataSource": {
"enabled": true,
"catalog": "clickhouse_data",
"schema": "modern",
"table": "software",
"mappedField": [
{ "sourceFieldName": "id", "targetFieldName": "id" },
{ "sourceFieldName": "name", "targetFieldName": "name" },
{ "sourceFieldName": "lang", "targetFieldName": "lang" }
]
}
},
"id": [{ "name": "id", "type": "STRING" }],
"attribute": [
{ "name": "name", "type": "STRING" },
{ "name": "lang", "type": "STRING" }
]
},
{
"label": "person",
"dataSourceGroup": {
"externalDataSource": {
"enabled": true,
"catalog": "clickhouse_data",
"schema": "modern",
"table": "person",
"mappedField": [
{ "sourceFieldName": "id", "targetFieldName": "id" },
{ "sourceFieldName": "name", "targetFieldName": "name" },
{ "sourceFieldName": "age", "targetFieldName": "age" }
]
}
},
"id": [{ "name": "id", "type": "STRING" }],
"attribute": [
{ "name": "name", "type": "STRING" },
{ "name": "age", "type": "INT" }
]
}
],
"edge": [
{
"label": "created",
"fromNodeLabel": "person",
"toNodeLabel": "software",
"dataSourceGroup": {
"externalDataSource": {
"enabled": true,
"catalog": "clickhouse_data",
"schema": "modern",
"table": "created",
"mappedField": [
{ "sourceFieldName": "id", "targetFieldName": "id" },
{ "sourceFieldName": "from_id", "targetFieldName": "from_id" },
{ "sourceFieldName": "to_id", "targetFieldName": "to_id" },
{ "sourceFieldName": "weight", "targetFieldName": "weight" }
]
}
},
"id": [{ "name": "id", "type": "STRING" }],
"fromKey": [{ "name": "from_id", "type": "STRING" }],
"toKey": [{ "name": "to_id", "type": "STRING" }],
"attribute": [
{ "name": "from_id", "type": "STRING" },
{ "name": "to_id", "type": "STRING" },
{ "name": "weight", "type": "DOUBLE" }
]
},
{
"label": "knows",
"fromNodeLabel": "person",
"toNodeLabel": "person",
"dataSourceGroup": {
"externalDataSource": {
"enabled": true,
"catalog": "clickhouse_data",
"schema": "modern",
"table": "knows",
"mappedField": [
{ "sourceFieldName": "id", "targetFieldName": "id" },
{ "sourceFieldName": "from_id", "targetFieldName": "from_id" },
{ "sourceFieldName": "to_id", "targetFieldName": "to_id" },
{ "sourceFieldName": "weight", "targetFieldName": "weight" }
]
}
},
"id": [{ "name": "id", "type": "STRING" }],
"fromKey": [{ "name": "from_id", "type": "STRING" }],
"toKey": [{ "name": "to_id", "type": "STRING" }],
"attribute": [
{ "name": "from_id", "type": "STRING" },
{ "name": "to_id", "type": "STRING" },
{ "name": "weight", "type": "DOUBLE" }
]
}
]
}
In the Web UI, click Graph in the sidebar, then Upload Schema, and select schema.json.
Upload via CLI
You can also POST the schema directly:
Querying the Graph
In the PuppyGraph Web UI, click Query in the sidebar. You can run graph queries in either Cypher or Gremlin.
The following query answers "What software was created by people that marko knows?"
There are two paths in the result: marko knows josh, who created lop and ripple.
Cleanup
Shut down and remove the containers: